
by Paul Näger, 30.10.2024
While current Large Language Models (LLMs) such as GPT can answer philosophical questions in an impressive breadth, there are limits to their detail knowledge. When pushed about facts that they do not have information on, they either start hallucinating or become repretitive.
Systems with retrieval augmented generation (RAG) try to solve this problem by enhancing LLMs with specific and detailed information. In the present case I have made accessible the complete Stanford Encyclopedia of Philosophy (SEP) to an LLM (by crawling the SEP and storing it as a corpus to a vector database). When a user asks a question, the system first searches in the SEP corpus for relevant passages (“retrieval”) and passes these passages as background information to the LLM (“augmented”) jointly with the user question. When generating the answer (“generation”), the LLM can access the relevant background information and give a more specific, detailed and informed answer.
I have written the code for the complete system and a prototype is now running. An impression of the backend (code) can be gained here:

The system’s frontend (user interface) is designed as follows:
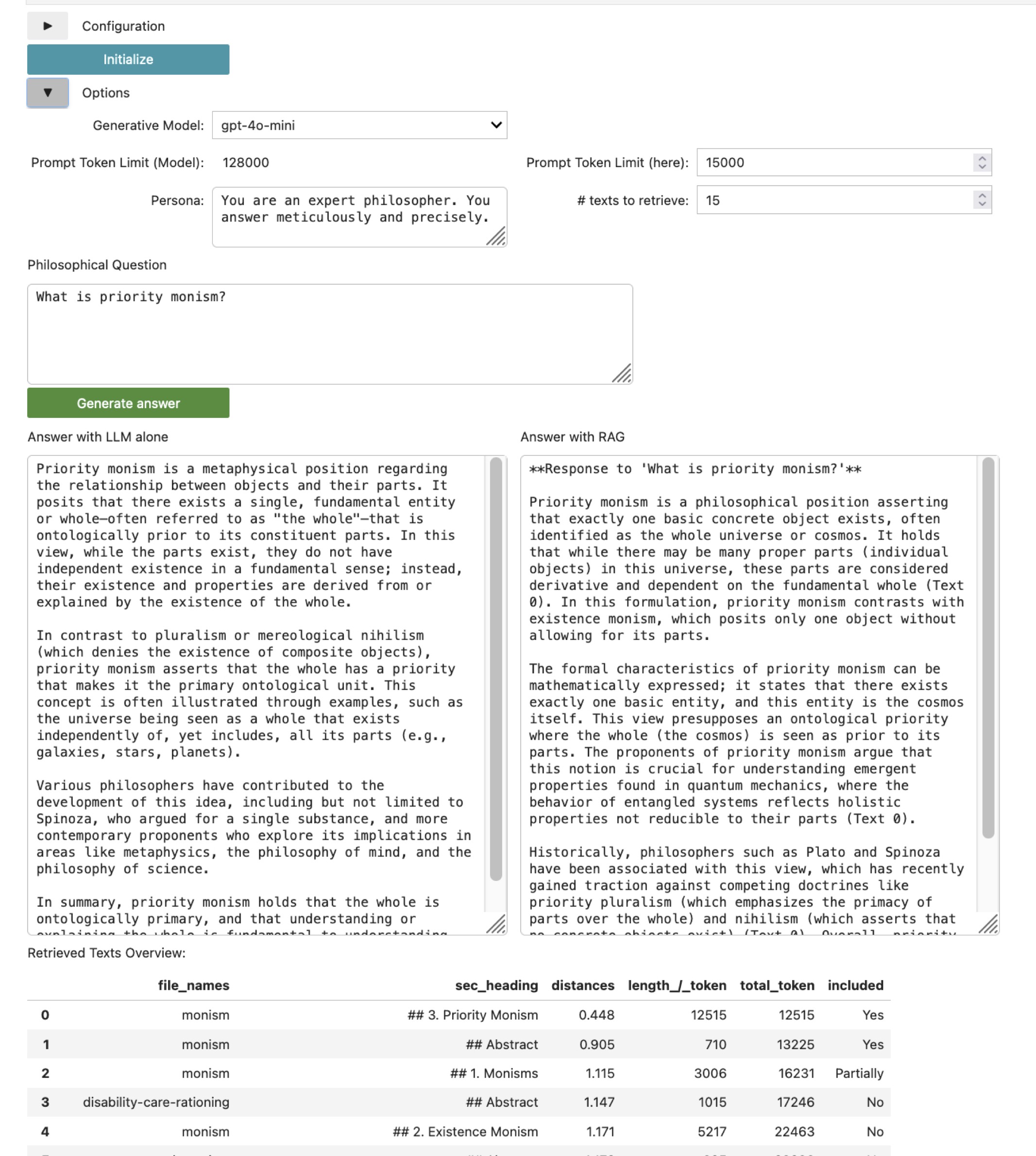
In the options section one can choose different parameters, namely the LLM that operates the system (gpt-4o-mini, gpt-4o, Llama-3.5-70B, mixtral-7B), a prompt token limit (restricting the amount of additional text that can be added to the question, thereby limiting also the costs), a persona statement (which is an effective prompt engineering strategy) and the number of texts to be retrieved from the SEP, where texts here are main sections of articles. Finally, there is a field for the user question.
There are two output fields: The left field provides the answer that the LLM outputs without additional information, while the right field is the answer of the RAG system. This layout allows to easily compare the quality of the two answering systems. In the above example the quality of the RAG system’s answer on priority monism is considerably more detailed, as the encyclopedia’s article on monism incorporates a long section on the topic. Usually, the answers of the RAG system are better the more specific and detailed the question is. The answer of the LLM alone tends to be better, when one aks for an overview of not too specific fields (e.g. “What are the main arguments for/against mental causation?”).
In contrast to the answer generated by the LLM alone, the RAG answer also refers to the source texts for the presented information (Text 0, …). The legend for these texts can be found in the table below the answer fields. The table lists the found relevant texts, where the field file_names indicates the short article name, and sec_heading the section that has been found in this article. The smaller the distance, the relevanter is the text for the question. The most relevant texts are included up to that text which exceeds the prompt token limit.
This short presentation shows that the RAG system has the potential to become an important research tool for professional (as well as interested laymen) philosophers.
(The prototype was demonstrated at the conference DGPhil, Sep 2024, Münster, Germany.)